
Agents zijn probabilistisch; productie is meedogenloos. De interessante vraag is niet "hoe maken we het model perfect" — het is "hoe bouwen we een betrouwbaar systeem uit een onbetrouwbaar onderdeel." Dat is in de engineering een opgelost probleem. We hoeven het alleen maar toe te passen.
Niets van wat volgt is exotisch. Het is dezelfde discipline die gedistribueerde systemen betrouwbaar maakt, gericht op een nieuw soort onbetrouwbaarheid. De teams die winnen met agents zijn degenen die ze behandelen als nóg een wankele afhankelijkheid, niet als magie.
Idempotentie eerst
De allerbelangrijkste eigenschap is dat dezelfde stap twee keer uitvoeren hetzelfde effect heeft als één keer. Op het moment dat je een retry wilt doen — en dat ga je doen — is idempotentie wat een retry veilig maakt in plaats van een manier om de klant drie facturen te sturen.
In de praktijk: geef elke actie een stabiele sleutel, controleer voordat je schrijft, en laat "aanmaken" betekenen "aanmaken of de bestaande teruggeven". Krijg je dit goed voor elkaar, dan is het grootste deel van je betrouwbaarheidsverhaal al geschreven, want nu mag je vrijuit retryen.
Je maakt een onbetrouwbare stap niet betrouwbaar door te hopen dat hij slaagt. Je maakt hem veilig om opnieuw te draaien.
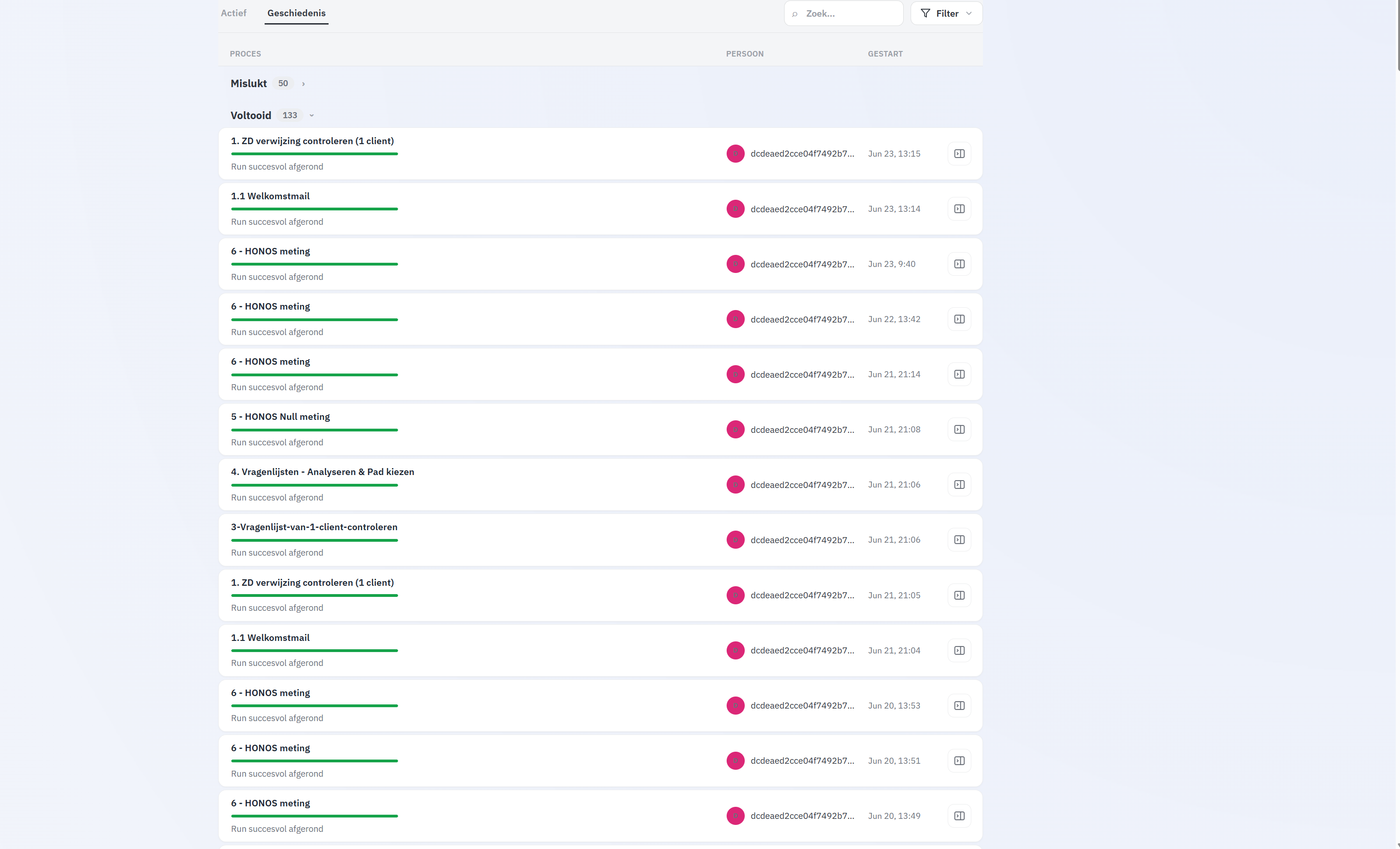
Observability die je daadwerkelijk leest
Wanneer een agent iets verrassends doet, zijn "de logs" zelden genoeg — je moet een beslissing reconstrueren. Daarom leggen we runs vast als traces, niet als regels: elke node, zijn invoer, zijn output, de gekozen tak en de timing. Als iemand vraagt "waarom heeft hij déze geëscaleerd?", dan is het antwoord een klik en geen archeologisch project.
De lat die we onszelf opleggen: zou een operator die de flow niet gebouwd heeft, uit de trace alleen al kunnen begrijpen wat er is gebeurd? Zo niet, dan is de observability niet af.
Beperk falen tot de node
Agents orkestreren als losse nodes — in plaats van als één uitdijende prompt — is op zichzelf al een betrouwbaarheidsbeslissing. Een fout blijft beperkt tot de node die faalde. De run pauzeert daar met zijn context intact, je retryt of herstelt die ene stap, en niets stroomopwaarts hoeft opnieuw te draaien. Kleine impactstraal, snel herstel.
Begrens de niet-determinisme
Je kunt een model niet deterministisch maken, maar je kunt het wel inkaderen:
- Valideer outputs tegen een schema voordat ze stroomafwaarts gaan — wijs het misvormde af voordat het zich verspreidt.
- Beperk tools zodat een agent alleen acties kan uitvoeren die je hebt goedgekeurd, en geen nieuwe kan improviseren.
- Stel budgetten in — tijd, retries, kosten — zodat een verwarde agent snel faalt in plaats van in een lus te blijven hangen.
Het model blijft creatief binnen het kader; het kader is wat productie vertrouwt.
Zet mensen op het onomkeerbare
Betrouwbaarheid is niet alleen technisch. De goedkoopste manier om nooit een verkeerde betaling te versturen is de agent geen betalingen onbeheerd te laten doen. Een mens-in-de-lus-checkpoint op onomkeerbare acties is een engineeringmaatregel die net zo legitiem is als een retry — en veel goedkoper dan het incident dat hij voorkomt.
De saaie conclusie
Er zit hier geen slimme truc achter, en dat is precies het punt. Idempotentie, tracing, isolatie, validatie, budgetten, checkpoints — de ondankbare machinerie van betrouwbare software. Agents hebben die regels niet afgeschaft. Ze gaven ons alleen een nieuwe reden om ze serieus te nemen.
Bekijk hoe runs, traces en checkpoints eruitzien in Rylo.
Demo aanvragen

